Walknet: Affective Movement Recognition and Generation
We build models to teach machines to recognize and synthesize affect expression through human movement. In particular, we investigate questions such as:
Can people perceive valence and arousal in motion capture without facial expressions?
Do people agree on what they see?
Can we train machine learning models using human ratings to classify movements of different affects?
Can we use deep learning for modelling and controlling the generation of motion capture-based movement information? In particular:
Can we integrate the control of multiple movement dimensions (function, planning, expression)?
Can the model generalize the movements to generate unseen combinations and qualities?
Can we use the model in interactive scenarios in which the responsiveness of the control is important?
Data Collection
Since we want to be able to control movement across the three dimensions of function, planning, and expression, we created our own data set and captured the movements of three professional actors and dancers (two female, one male).
The performers carry out 9 different types of movements:
Walking in a figure eight pattern
Hugging the other performer
Standing idle
Free improvisation
Sitting down
Pointing while sitting
Walking with sharp turns
Improvisation with the other performer
Lying down.
Each movement type is performed with multiple expressions, corresponding to the 9 different possible valence and arousal combinations as shown in Affect Representation. Each valence and arousal combination is repeated 4 times to capture the existing motor variabilities.


The motion capture data can be found at: http://moda.movingstories.ca/projects/29-affective-motion-graph
Affect Recognition
Valence 8-walk ratings

Arousal 8-walk ratings

Valence sharp walk ratings

Arousal sharp walk ratings

Inter-rater agreement, measured with Cronbach’s α:

Categorical approach:
Support Vector Machines: 43% accuracy
k-Nearest Neighbour: 54% accuracy
Hidden Markov Models: 73% accuracy
Continuous approach:
Stepwise linear regression, measured with coefficient of determination (R2): 0.925 for valence, 0.985 for arousal.
Affect-Expressive Movement Generation
We are developing a multidimensional agent movement controller, modelling the function, execution, affect-expression, personal style, and planning dimensions of movement. The system is designed and built iteratively in three stages.

In the first iteration, we only model the expressive dimension.
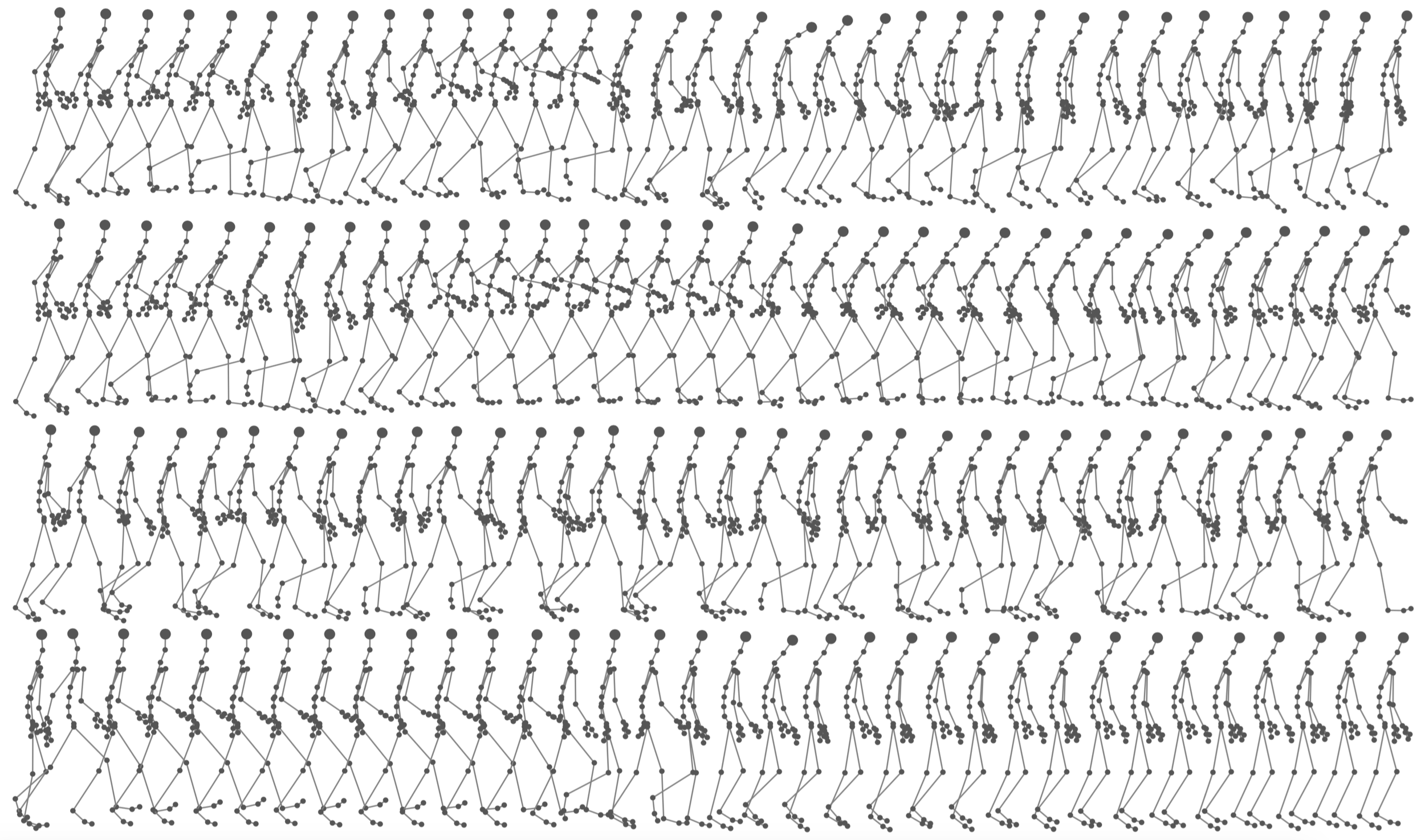
In the second iteration, we add the planning dimension, as well as the choice of personal movement signature.
In the third iteration, we add the functional dimension, which allows us to transition from one action to another.
Members
Omid Alemi, William Li, Philippe Pasquier
Research papers
O. Alemi, W. Li and P. Pasquier, "Affect-expressive movement generation with factored conditional Restricted Boltzmann Machines," Affective Computing and Intelligent Interaction (ACII), 2015 International Conference on, Xi'an, 2015, pp. 442-448.
Li, W., and Pasquier, P., “Automatic Affect Classification of Human Motion Capture Sequences in the Valence-Arousal Model,” To Appear in Proceedings of the 3rd International Symposium On Movement & Computing, 2016, Thessaloniki, Greece.